ビジネス現場のコミュニケーションツール「LINE WORKS」を提供するLINE WORKS株式会社(本社:東京都渋谷区、代表取締役社長:増田 隆一)は、AI技術を活用した音声記録管理サービス「CLOVA Note β」において、日本語に特化した汎用大規模言語モデル(RoBERTa)を活用したフィラーや言い淀みを除去する新機能※を提供開始したことをお知らせします。
※本機能は過去作成されたノートには適用されず、新規作成ノートにのみ適用されます。また自動的に適用されるため、アプリアップデートを行う必要はありません。
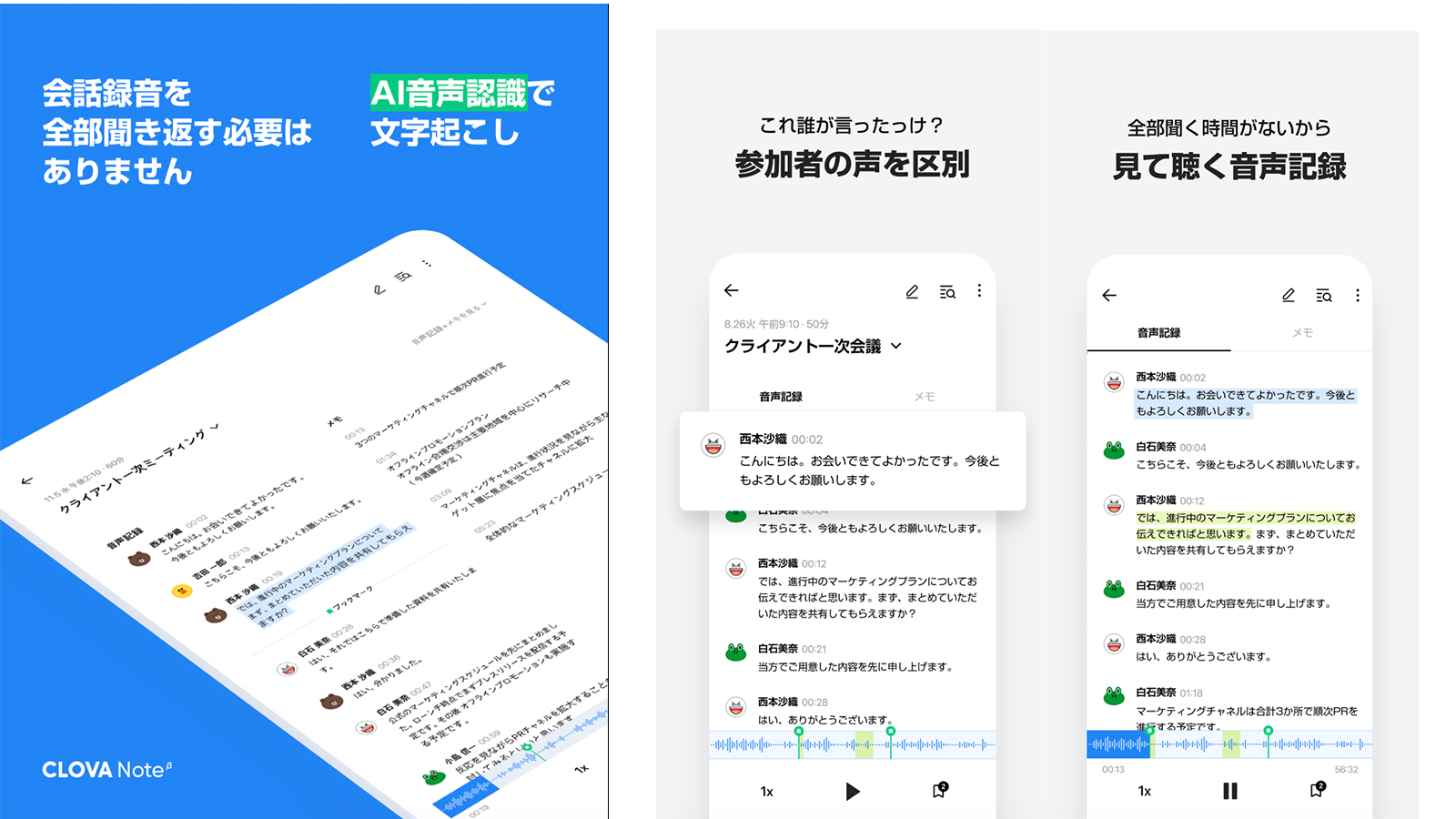
「CLOVA Note β」は、高精度のAI技術を活用した無料の音声記録管理サービスで、手軽に音声を文字に変換します。
今回追加されたフィラー・言い淀み除去機能は、話者が発する「えー」「あのー」といったフィラー・言い淀みをAIが自動的に識別し、除去する技術です。これにより、文字起こしされたテキスト内の不要な言葉が削除され、より自然でクリアなテキストに変換することができるようになり、ノート全体の読みやすさや理解のしやすさを大幅に改善しています。
さらに、「あの」や「その」のような指示代名詞などの重要な単語が誤って削除されないよう、文脈に応じたテキストの保持または除去が判断されるように調整しています。
<CLOVA Noteβを利用した会話例>

■ LINE WORKS社在籍の専門チーム・エンジニアの緻密な分析と研究により
高精度な日本語音声認識モデルの開発を実現。
「CLOVA Note β」で活用されているAIと技術について
「CLOVA Note β」では、人の話す言葉を音声として認識し、これをテキスト化する音声認識が使用されています。この音声認識では、音声データそのものからAIモデルを学習し、正解ラベルを利用せずにモデルを構築する手法(自己教師あり学習という技術)が活用されていますが、従来のEnd-to-End音声認識※とは違って、大量の音声データを用いてAI学習を行うため、効率的に精度を向上させることができます。
※従来のEnd-to-End音声認識は、莫大な音声データと正解ラベルの人的作業がペアで必須となるため、精度向上に不可欠な品質の良い学習データを集めるのに多大なリソースと時間がかかることが課題といわれている。
このような高精度な日本語音声認識モデルの開発・提供ができる背景として、LINE WORKS株式会社には、高品質な正解データを生成するための専門チームや、誤認識結果の分析や先行研究などを参考に音声精度の向上に取り組む優れたリサーチエンジニアが在籍しており、これがAI技術を提供する上での強みになっています。
■ フィラー・言い淀み除去機能の開発背景
可読性・音声認識後処理技術の向上のために工夫したポイント
フィラー・言い淀み除去モデルの開発は、「不要な言葉が含まれるとノートの可読性が低下し、内容の把握が困難になる」というユーザーからの声を反映し、ユーザーエクスペリエンスを最重視して開発しました。開発の初期段階では、ユーザーの意図に沿っているか、また発話内容から重要な情報を削除してしまうような処理を行っていないかを特に意識し、開発および性能評価を繰り返しました。
またこの他にも、文字単位での効率的な識別や高い精度でフィラーや言い淀みの検出に向けてさまざまな工夫を施すことで、音声認識結果から不要な要素を取り除き、読みやすさを格段に向上させています。
・文字単位での効率的な識別
自然言語処理(NLP)タスクにおいて高い性能を発揮するRoBERTaを用い、適切なモデルの選択やテキストの前処理に重要な役割を果たす「モデルのサイズ」と「トークナイザー※」には、フィラーと言い淀みの検出という下流のタスクに合わせて最適化されるよう事前学習しています。「トークナイザー」は日本語の文字ベースのものを使用することで、フィラーや言い淀みなどを文字単位で効果的に識別できるよう工夫しています。
・高品質なデータからフィラーや言い淀みを高い精度で検出
フィラー・言い淀み除去モデルの完成度を高めるための微調整(fine-tuning)においては、ドメインミスマッチを防ぐために正解テキストデータも使用しています。専門チームによってアノテーションされた高品質なユーザーデータ※を、サービスの向上のための情報源として活用することで、フィラーや言い淀みを高い精度で検出するモデルを実現しています。
※文章やテキストを小さな単位に分割するツールのようなもの。文章を単語や文字などの部分に分けることができるため、機械学習をする際にAIが理解しやすい形に変換することができる。
※ ユーザーデータは、「サービス品質向上のためのユーザーデータの取得」で同意したユーザーのみのデータを利用。
「CLOVA Note β」とは?
https://clovanote.line.me/
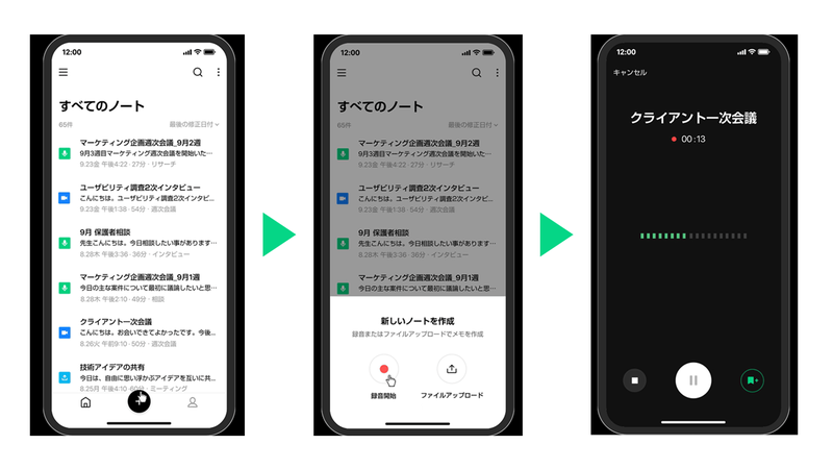
CLOVA Note βは、高精度のAI技術を活用した無料の音声記録管理サービスで、手軽に音声を文字に変換します。 シンプルで使いやすいUIで、面倒な録音からの書き起こし、会議の議事録作成、授業でのノート作成といった作業の手間を省きます。最大180分の会話を変換可能で、3人以上の会話ではAIが話者を区別し各話者ごとに会話を分けて表示します。
・言語:日本語、英語、韓国語、中国語(簡体字/繁体字)の認識に対応
・デバイス:スマートフォン、タブレット、PCのマルチデバイスに対応
・機能:ファイルダウンロード、話者分離、共有機能、ノイズリダクション、倍速再生可能な再生スピード調整、変換したテキストの編集、キーワード表示、既存の音声ファイルからのテキスト変換など
■会社概要
社名:LINE WORKS株式会社
本社:東京都渋谷区神宮前1-5-8 神宮前タワービルディング11F
設立:2015年6月
代表者:代表取締役社長 増田 隆一
資本金:55億2,000万円
URL:https://line-works.com/jp/
※記載の会社名、製品名は、それぞれの会社の商標または登録商標です。
※本プレスリリース記載の情報は発表日現在の情報です。予告なしに変更されることがありますので、予めご了承ください。


