以下の箇所からドメイン単位で確認することが出来ます。
・Consoleにログイン>サイドメニュー [CLOVA OCR] > [Management]
また、Template OCRの場合はテンプレートビルダからも確認が可能です。
・Consoleにログイン>サイドメニュー [CLOVA OCR]>[Domaim]>[テンプレートビルダー]>[指標]
なお、Template OCRは一度の読み取りがフィールド50個で1枚換算となります。
いずれも、表示される読み取り数は上記単位で換算後の数字が反映されています。
例)70個のフィールドを一度に読み取った場合 = 2枚換算 / 120個のフィールドを一度に読み取った場合 = 3枚換算
可能です。
テンプレートの引き継ぎ方法は、インポート方法をご確認ください。
https://line-works.com/ai-product/ocr/user-guide/template-ex-import/
可能です。
JavaScriptを使用してAPIリクエストを行う場合、CORS設定が必要となります。
ブラウザから異なるオリジンへのリクエストを行う際、セキュリティ上の理由からブラウザは適切なCORS設定がサーバー側に設定されていない場合、リクエストをブロックします。
このため、APIをブラウザから安全に呼び出すには、CORS設定を行う必要があります。
CORS設定はAPI Gatewayで行うことができます。以下の手順に従って設定をお願いします。
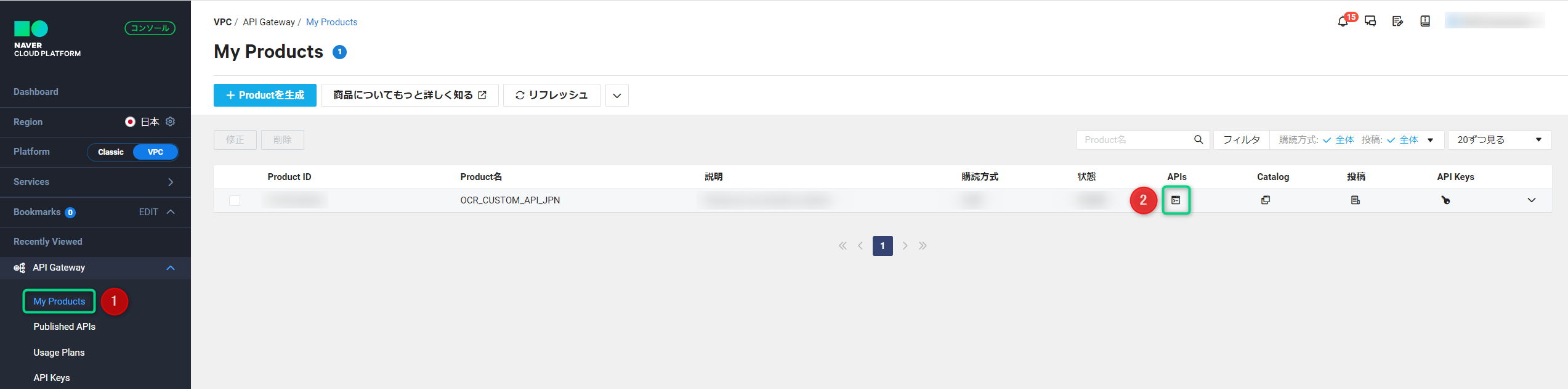
- 1. API Gateway > My Productsにアクセス
- 2. 該当のProductの”APIs”をクリック
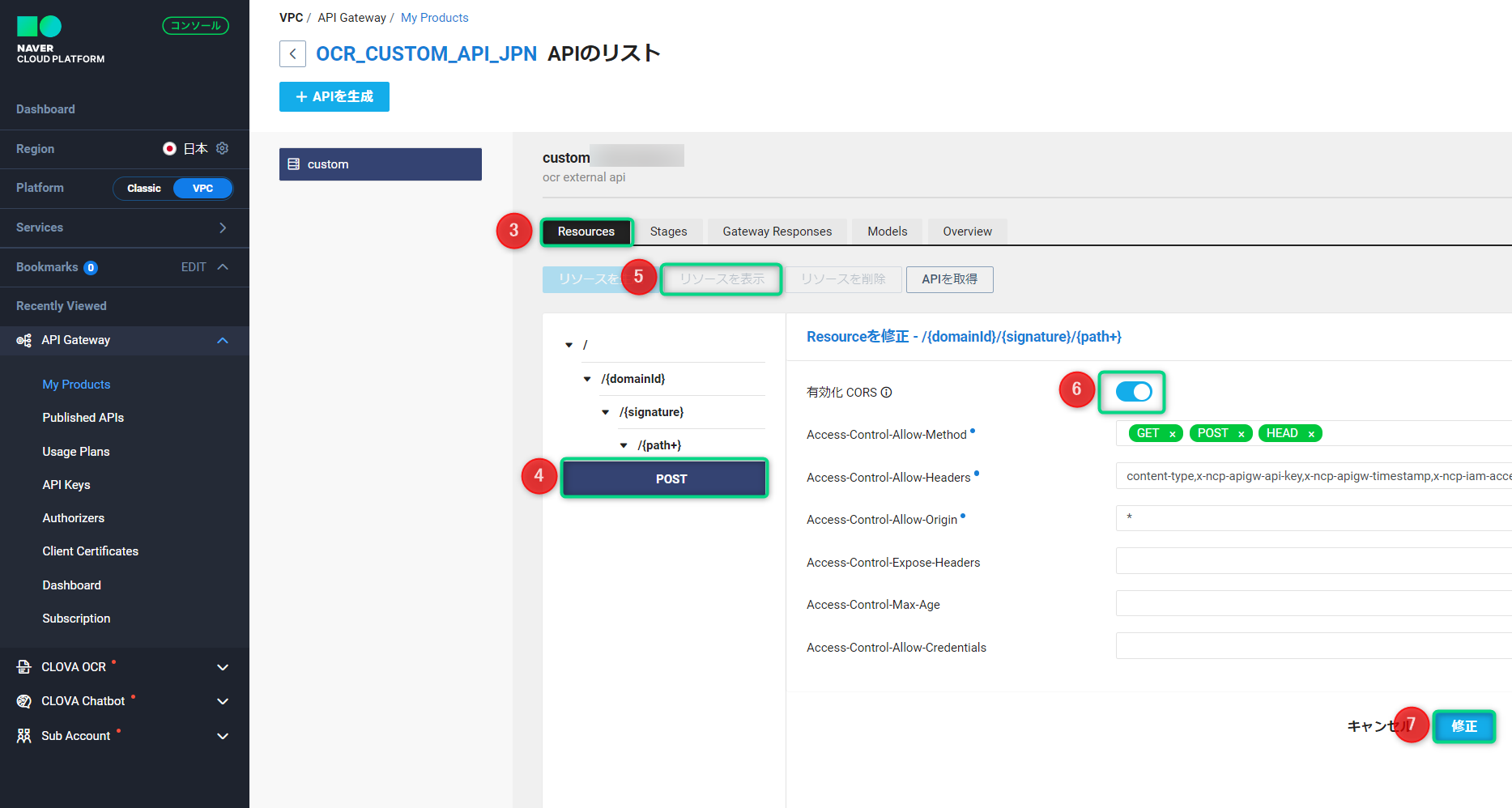
(自動連携をしていた場合はProduct名が「OCR_CUSTOM_API_JPN」) - 3. 「Resources」をクリック
- 4. 「Post」をクリック
- 5. 「リソースを表示」をクリック
- 6. 「有効化 CORS」をオンにする
- 7. 「修正」をクリック
可能です。
API Gatewayから設定を行います。
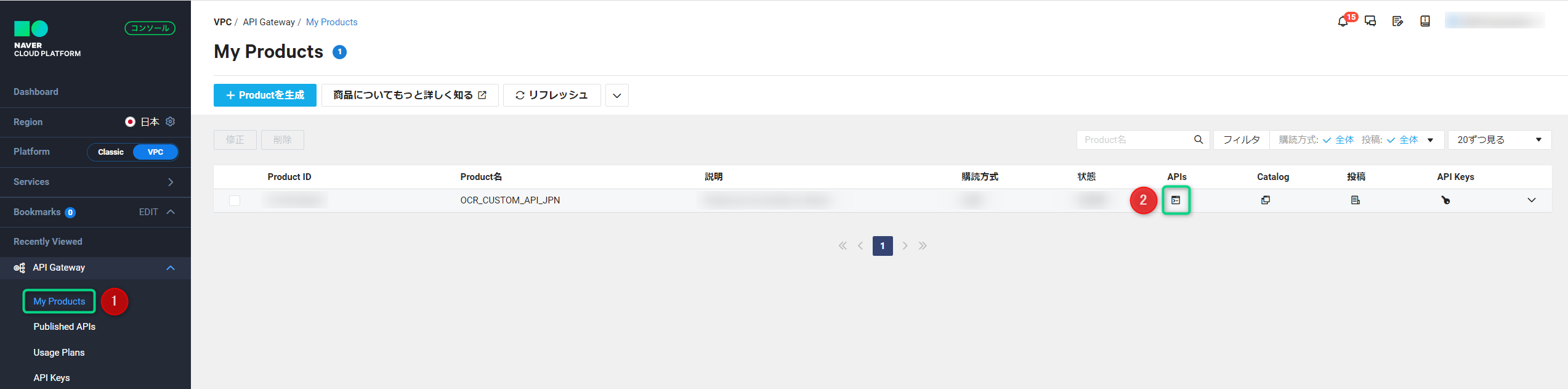
- 1. API Gateway > My Productsにアクセス
- 2. 該当のProductの”APIs”をクリック(自動連携をしていた場合はProduct名が「OCR_CUSTOM_API_JPN」)
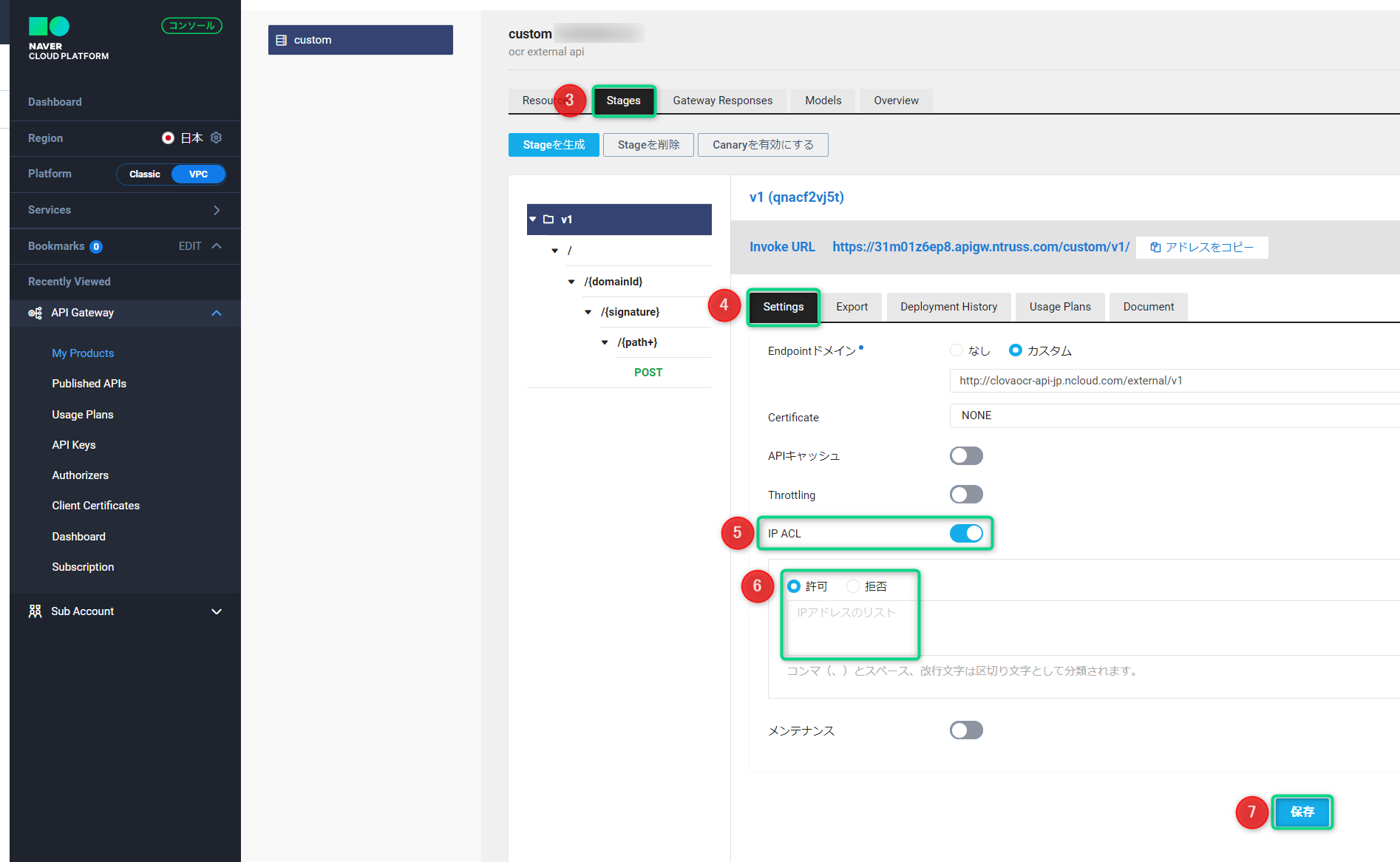
- 3.「Stages」をクリック
- 4.「Settings」をクリック
- 5.「IP ACL」をクリック
- 6. IPアドレスを指定し、受信または拒否を選択
- 7.「保存」をクリック
可能です。
API Gatewayから設定を行います。
なお、こちらの設定を行うとリクエスト時にSecret keyとは別にAPI Keyをheaderに追加する必要がございます。
- 1. API Gateway > My Productsにアクセス
- 2. 該当のProductの”APIs”をクリック(自動連携をしていた場合はProduct名が「OCR_CUSTOM_API_JPN」)
- 3. Stageタブをクリック
- 4. 「Usage Plan」の子タブをクリックし、「修正」
- 5. 「リクエスト処理の上限」をオンにし上限値を指定し保存
- 6. API Gateway > API Keys にアクセス
- 7. 「API Keyを生成」をクリックし、APIの名前と必要に応じて説明を入力し保存
- 8. API Gateway > My Products に戻り該当のProductの”API Keys”マークをクリック
- 9. 「自分のAPI Keyを追加」をクリックし、7で生成したAPI Keyにチェックを入れ追加
- 10. APIのリクエスト時にx-ncp-apigw-api-key: {API KeyのPrimary またはSecondary Key} をheaderに指定してください
LINE WORKS OCRの間でトラフィックを管理しているハブとなるサービスです。
NAVER Cloudのサービスを使用する場合には原則併せて利用するものとなります。
(基本ご利用は無料です)
申請方法はこちらをご参照ください。